|
|
Hidden Markov Model Based Classification in Personalized Education |
INVESTIGATORS
Dr. Yisong Chen et al.
KEYWORDS:
Hidden Markov models , Pattern classification, EM optimization, Viterbi algorithm, Model selection, Bayesian information criterion, Hypothesis test.
BRIEF DESCRIPTION
This work aims at exploiting the capabilities of hidden Markov models for smart user characterization in web based learning system. Our objective is to investigate whether the HMM approach can successfully distinguish between two specific student groups based solely on their navigation patterns in a web-based learning system. Specifically, we stress the issues of model selection and initialization, which are critical to the success of relevant applications but have long been ignored in related literature.
The students are ranked according to their English performance in the past year, and two groups of students are chosen based on this ranking. The first group (Group A) consists of students ranked in the top 30, and the secod group (Group B) consists of the last 30 students in the ranked list. Since Chi-square goodness-of-fit test shows significant difference between these two groups, we attempt to do more work to see whether we can characterize individual behaviors through a statistical pattern classification model. In each group, 20 students are selected at random and their navigation sequences are used as the training data set while the others form the test data set.
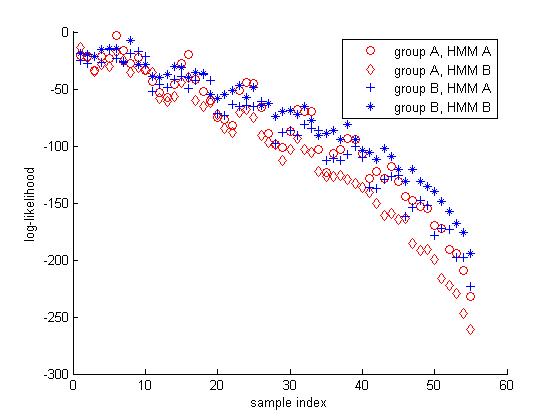
For each group of students under study, a corresponding HMM is constructed to model their navigation behavior, which we denote as HMM A and HMM B respectively. Random transition matrix initialization is employed to guarantee global optimal solution. The number of hidden states is selected by Bayesian information criterion (BIC). The minimal score function values is achieved under the models of 3- or 4-state topology. Following are the test results on 3-state HMM model and 4-state HMM respectively with longer sequences corresponding to larger sample index. The performances are comparable.
Figure 1. Test results for 3-state HMM.
The global classification accuracy is 90.91% for group A and 89.09% for group B test data.
Figure 2. Test results for 4-state HMM.
The global classification accuracy is 92.73% for group A and 87.27% for group B test data.
The above figures show intuitively that for most samples the “*” marks are associated with higher log-likelihood values than the corresponding “+” marker. Similar conclusion can be drawn with respect to the circle marks and the diamond marks. This means that the HMM can effectively distinguish between students of different categories.
An interesting observation is that the results of the two HMMs for a single test sample are more separable for longer sequences and the accuracy increases with the increase of the length of the test sequence. When the length of the sequence exceeds 60 the accuracy reaches 100%. This shows that the model has some error resilient function capable of correcting early mistakes. This is not surprising because the Viterbi algorithm employed here is per se a powerful error correction algorithm in the area of channel coding.
FUNDING AGENCY
N/A
PUBLICATIONS
Apple W P Fok, H S Wong and Y S Chen, Hidden Markov Model Based Characterization of Content Access Patterns in an e-Learning Environment, ICME'2005, In press.